
- Compile a list of papers: try to create a list of research papers, posts and whatever text or learning resource you have.
- Skip around the list: basically, you should read research papers in a parallel fashion; meaning try to tackle more than one paper at a time. Concretely, try to quickly skim and understand each of these paper and do not read it all, maybe you read 10–20% of each one and probably that will be enough to give you a high-level understanding of the paper in hand. After that, you may decide to eliminate some of these papers or just go over one or two them and read them fully.
He mentioned also that if you read:
5–20 papers (in a field of choice, say speech recognition) => it may be probably enough knowledge for you to implement a speech recognition system, but maybe not enough to research or be at the cutting-edge.
50–100 papers => you probably have a very good understanding of the domain application (speech recognition).
논문의 전체를 읽지 말고 아래와 같이 읽어라.
- Read the Title, the abstract and the figures: by reading the title, abstract, the key network architecture figure, and maybe the experiments section, you will be able to get a general sense of the concepts in the paper. In deep learning, there are a lot of research papers where the entire paper is summarized in one or two figures without the need to go hardly through the text.
- Read the introduction + conclusions + figures + skim the rest: the introduction, the conclusions and the abstract are the places where the author(s) try to summarize their work carefully to clarify for the reviewer why their paper should be accepted for publication.
Also, skim the related work section (if possible), this section aims to highlight work done by others that somehow ties in with the author(s) work. Hence, it may be useful to read it but if you’re not familiar with the literature, it is sometimes very hard to understand.
- Read the paper but skip the math.
- Read the whole thing but skip the parts that don’t make sense: great research means we’re publishing things at the boundaries of our knowledge and understanding.
He also explained that when you read papers (even the most influential ones), you’ll find maybe some parts that is much less used or it doesn’t make sense. Consequently, it’s fine if you read a paper and some of it doesn’t make sense (it’s not unusual), it’s okay to skim it initially. Unless, you’re trying to master it, then spend more time.
위와 같은 방법으로 읽은 후에, 아래의 질문에 대답할 수 있도록 해라.
- What did the author(s) try to accomplish?
- What were the key elements of the approach?
- What can you use yourself?
- What other references do you want to follow?
state-of-the-art of deep learning을 따라가기 위해서 논문을 읽는게 필수인 것 같다. 어떻게 읽어야하는지 가이드라인을 언급해준 영상과 요약글이 있길래 긁어왔다. 시간은 걸리겠지만 밑바닥에서부터 논문의 내용을 구현하는 것이 좋은 연습이 될 것이라고 강조했다.
좋은 머신러닝 엔지니어의 구조
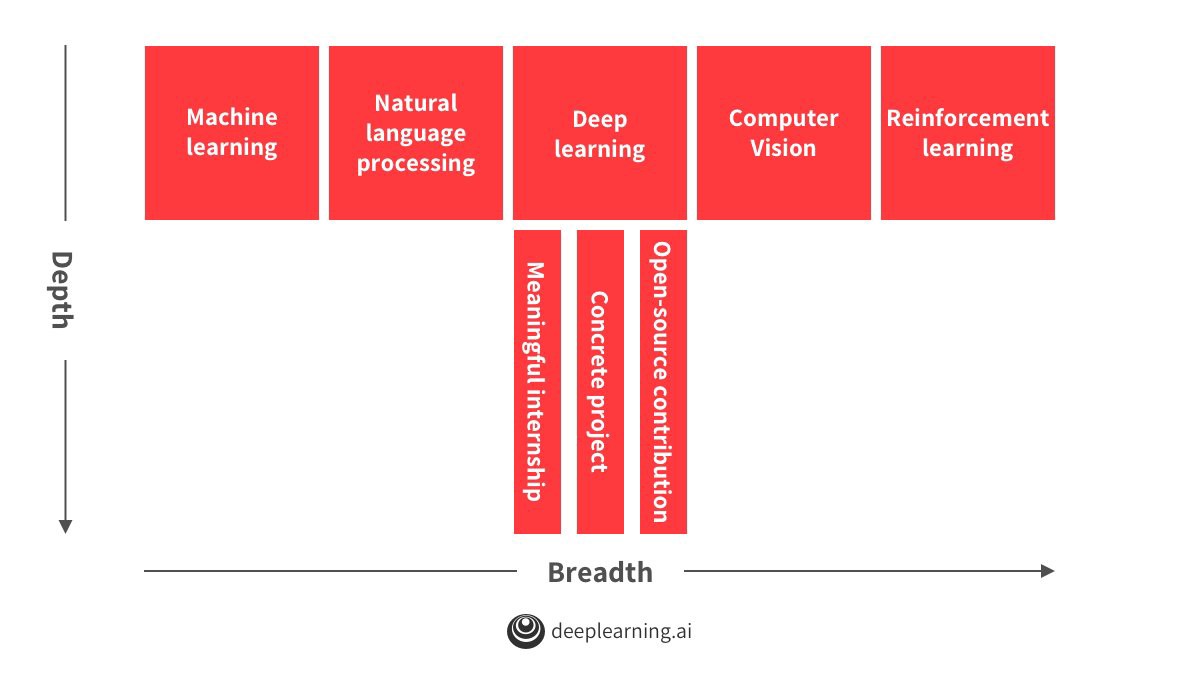
요점:
- Develop a habit of reading research papers: maybe 2 papers a week as a start.
- Read efficiently: compile a list of papers, read more than one paper at a time and take multiple passes through each one.
- When reading a paper: start by reading the title/abstract/figures (especially)/introduction/conclusions.
- When trying to understand an algorithm: try to rederive the math and practice coding by reimplementing it.
- Try to stay on top of things: by checking papers in ML conferences and other online resources.
- Build a T-shaped knowledge base in AI.
- Try to join a good team (in a big company or a startup) that will help you grow efficiently.
- Work on useful projects that helps you learn the most and moves the world forward.
- Try to take machine learning to other industries: healthcare, astronomy, climate change, etc.
Advice on building a machine learning career and reading research papers by Prof. Andrew Ng - KDnuggets
This blog summarizes the career advice/reading research papers lecture in the CS230 Deep learning course by Stanford University on YouTube, and includes advice from Andrew Ng on how to read research papers.
www.kdnuggets.com
'Computer Science > [21-22] ML & DL' 카테고리의 다른 글
| [FE] 시계열 데이터 lag feature 추가하기 (0) | 2022.04.15 |
|---|---|
| [LSTM] LSTM unit, cell, layer에 대한 이해 (0) | 2022.04.13 |
| [LSTM] keras.layers.LSTM()의 input_shape (0) | 2022.04.10 |
| [cv] LOOCV vs K-Fold and bias-variance trade-off (0) | 2021.11.22 |
| [EDA] Pandas.skew() 가 skewness를 계산하는 방법 (0) | 2021.11.19 |


댓글